CoreDNS problems with Mikrotik router

Problem?
When working on Elastic/Prometheus integration (long-term storage) I noticed weird problems with DNS resolution. Namely, Prometheus pod was not able to resolve my Elastic Cloud instance hostname.
Verified with CoreDNS graphs, that there is something weird going on:
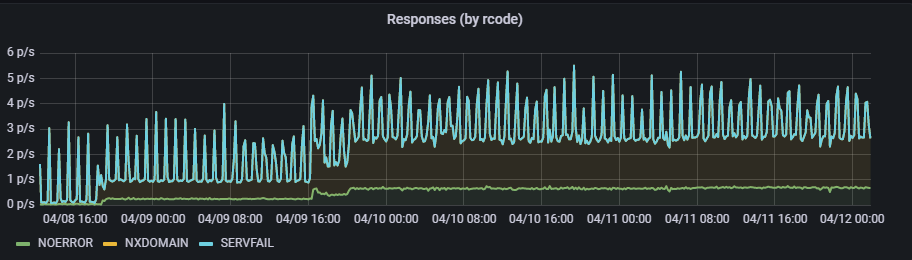
So dug into coredns/nodelocaldns DaemonSets pods logs, and found following problems:
[ERROR] plugin/errors: 2 netrunner.es.eu-central-1.aws.cloud.es.io. A: dns: overflow unpacking uint32
[ERROR] plugin/errors: 2 netrunner.es.eu-central-1.aws.cloud.es.io. A: dns: overflowing header size
[ERROR] plugin/errors: 2 netrunner.es.eu-central-1.aws.cloud.es.io. A: dns: buffer size too small
Wow, weird. I quickly verified w/tcpdump and wireshark, that indeed DNS payload in UDP dataframes getting back from my DNS server (Mikrotik RouterBoard RB750Gr3) were much bigger for this query.
DNS has this limit of 512 bytes for UDP for a reason (it guarantees that DNS packets can be reassembled if fragmented in transit). For larger payloads TCP is used.
So in my case, looks like DNS server returned a bigger DNS UDP payload than RFC allows. And CoreDNS didn't really like it.
Solution?
I quickly took a look at router configuration options (RouterOS) referring to DNS, and quickly realized, that by default:
max-udp-packet-size (integer [50..65507]; Default: 4096) Maximum size of allowed UDP packet.
Verified this w/my router configuration and that was it. The solution was to:
/ip dns set max-udp-packet-size=512